
Search Engine Optimization (SEO) is a bit of a mystery for most developers. So, I’ve put together this checklist of SEO essentials that will make your SEO team and your client very happy.
Inspect the HTML source code
Get picky about HTML source code:
- Is your HTML structure valid? Valid HTML structure makes the page easier for search engines to parse. You can validate it here.
- Do all pages include proper head elements, with a single title element and meta description? The title element (most people call it the “title tag,” but we know better) is the single strongest on-page ranking factor. The meta description is what shows up in the search snippet.
- Can CMS users edit the meta description and title element on every page? They’re going to need to.
- Does every content page (not paginated lists of multiple pages) have a single H1 tag? See valid HTML structure, above.
- Are image alt attributes defined for all images? ALT attributes are a strong ranking signal.
HTTP header statuses
Your pages must return proper HTTP statuses. We often take this for granted – many applications use the right HTTP status codes out of the box. But we have run into a handful of issues over the years. It’s worth double-checking:
- Missing pages must return a 404 response, not 200. A 200 response can create duplicate content and waste valuable crawl budget.
- Permanent redirects must return a 301 response, not 302.
Two easy ways to check the status returned by the hosting server are Google Chrome console, or (my favorite) redbot.org.
In Chrome: Open console (ctrl + shift + j on windows) and traverse to the “Network” tab. Refresh the page you want to test and inspect the first row with the page URL. The “Status” column is your HTTP status.

Portent.com returning HTTP status of 200
For redbot.org, enter the full URL you want to test and analyze the return header:
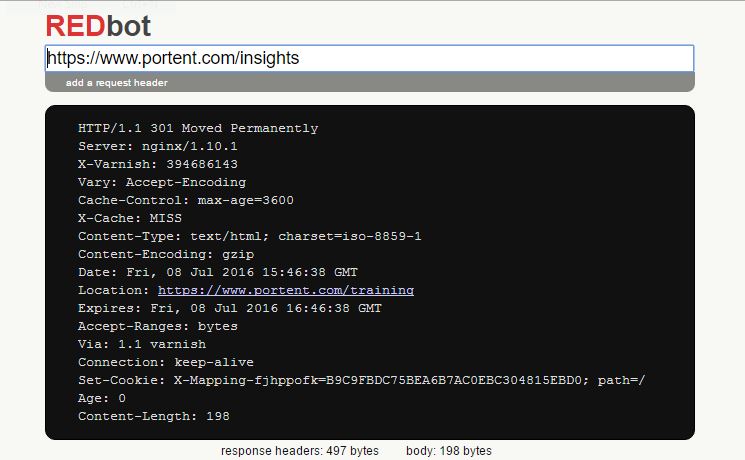
redbot.org 301 check for portent.com/insights
Create a base robots.txt file
Help your SEO team out by implementing a solid robot.txt as a good starting point.
Portent’s resident SEO developer, Matthew Henry, wrote a great article on all things robots.txt. Definitely worth a read! I’ll only touch on a basic approach to robots.txt here.
- Include a link to an XML sitemap. Verify generation and add it to the top of the file.
- Set crawl-delay. While this is a non-standard, it doesn’t hurt to throttle the crawler bots that do read and follow it. This can help reduce load on your server.
Here is a basic robots.txt example:
Sitemap: https://www.portent.com/sitemap_index.xml User-agent: * Crawl-Delay: 10
Your SEO team will probably want to add some Disallow directives. Coordinate with them they have crawled the site and done some analysis.
Trailing Slashes
Oh, trailing slashes… one of the biggest banes of a web developer’s existence. I’m not sure how many times I’ve asked, “Who gives a sh*t?!?.” Turns out, search engines do. I know search engines care and understand why, but that doesn’t stop me from hating it a little. Regardless, make sure you handle them.
Here are a few approaches to handling trailing slashes.
301 redirect counterpart URLs
Make sure your URLs follow a consistent pattern with a redirect.
Example Apache .htaccess rewrite rule for adding trailing slash:
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^.*[^/]$ /$0/ [L,R=301]Note: Test thoroughly! This is just an example.
Example nginx config rewrite rule for adding trailing slash.
if ($request_filename !~* .(gif|html|htm|jpe?g|png|json|ico|js|css|flv|swf|pdf|doc|txt|xml)$ ) {
rewrite ^(.*[^/])$ $1/ permanent;
}Note: Test thoroughly! This is just an example.
Example IIS web.config rewrite rule for adding a trailing slash.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<system.webServer>
...
<rewrite>
...
<rules>
...
<rule name="trailing slash rewrite" stopProcessing="true">
<match url="(.*[^/])$" />
<conditions>
<add input="{REQUEST_FILENAME}" matchType="IsFile" negate="true" />
<add input="{REQUEST_FILENAME}" matchType="IsDirectory" negate="true" />
<add input="{REQUEST_FILENAME}" pattern="(.*?)\.html$" negate="true" />
<add input="{REQUEST_FILENAME}" pattern="(.*?)\.htm$" negate="true" />
<add input="{REQUEST_FILENAME}" pattern="(.*?)\.aspx$" negate="true" />
</conditions>
<action type="Redirect" url="{R:1}/" redirectType="Permanent" />
</rule>
...
</rules>
...
</rewrite>
...
</system.webServer>
</configuration>
Note: Test thoroughly! This is just an example.
Plugins/Extensions/Modules
Many CMS applications can handle this programmatically, either as an option/feature built into the core or via an extension, module, or plugin. I know that WordPress, Drupal, and Joomla all have this available.
Canonical tags
This is a last resort. If you are unable to utilize one of the other 2 methods above, you can use rel=canonical. If implemented correctly, canonical tags can help search engines figure out which URL to index. But canonical tags can cause unforeseen problems if not carefully implemented, and they’re a hack, not a real fix. Read Ian’s post on Search Engine Land for more about this.
Page speed
We’ve written a lot of articles on how page speed is a huge factor for SEO. ← Seriously, check them out. These 4 page speed factors should be at the top of your list to implement:
- Browser caching
- Page caching
- Minification
- Image compression
If you use WordPress, I wrote a detailed article about how to configure W3 Total Cache to handle most of these caching methods.
301 Redirects
I may have implemented more 301 redirects than anyone else on the planet. They also happen to be another bane of my existence. Many of the 301 redirects I implement are to fix bad inbound links from 3rd party sites. Perfect example:
Redirect 301 /109568960804534353862 https://www.portent.com/
But, if that link happens to generate a lot of incoming traffic, it is important to send the user to something better than a 404. This is generally the case for all 301 redirects — we want to preserve link authority, but also maximize a visitor’s experience by serving a page that’s relevant to what they are looking for, regardless of whether they found a stale link.
Here are 3 best practices around 301 redirects that should all web developers should consider.
Create 301 Redirect Map
A 301 redirect map is just a spreadsheet defining old URLs and their redirect targets. We always create redirect maps when migrating a client to a new site or platform. But they’re also good if you’re reworking URLs and/or site structure. Often your SEO team will provide this for you, but if you’re dealing with a major site migration, something like Drupal to WordPress, plan to generate a redirect map to guide the process. Trust me: It minimizes risk of catastrophic broken link messes. It also minimizes cleanup necessary after launch.
You can streamline the process.
Say you’ve created a custom script that queries the old site database and inserts old pages into the new application. Either create a mapping db table with old and new URLs, or create an attribute for each page that defines its old URL. You can then use this data to either generate 301 redirects in whatever web server you’re using (IIS, Apache, nginx), or you can create a 404 handler that checks the database for a matching URL and redirects accordingly.
Don’t do this programmatically, though. Use the database or attribute to generate a web server configuration directive. There’s less overhead.
Avoid multiple redirects
Redirect hops are not good for link authority, indexing, or site performance. Many times, especially with older sites, you’ll find redirect chains. Consolidate them so there’s a single redirect.
Do not 302 redirect
Unless the URL you are redirecting is truly temporary, do not use a 302 redirect. Be sure to understand the difference between 301 and 302 redirects. Simply put, 301 is permanent, and 302 is temporary — and we rarely see temporary directs. Use what’s technically correct.
Conclusion
Development that ignores modern SEO best practices is bad for the business. It also means cleanup projects later one. It’s easier to do it right at the beginning.
Take a proactive approach to SEO development. Learn best practices and use them from the start. It will lay the foundation for your client’s or your company’s site. It’s an approach web developers need to try more — as well as simply saying yes more. But that’s a topic for another day.